I completely agree with Will Motil’s assessment with an additional caveat.
No matter how you design a confrontational game as you describe yours to be, all such “enemies” as well as player entities will be supported by a single or possibly multiple object structures for each. All simulations are designed this way as is any type of confrontational type of game. The object structures store all the necessary data in a compartmentalized form.
Object structures will take up quite a bit of memory, even if virtualized, and as such will yield a declining level of performance no matter how you store such data as the numbers of such entities increase dramatically. This is just as true for in-memory representation as it is for disk-based storage.
In this case you may be better off considering a high speed object database that also has in-memory capabilities, which will be separate from the applications space.
I have just gone through a design phase for the storing and accessing of 4000 hexagonal objects representing my map-board and it took me over a week of tinkering and refining an idea into a somewhat efficient concept just for this aspect of my own simulation. The addition of AI for the computer-based opponents will most likely have an underlying RDBMS supporting therm out of necessity.
The most efficient technique, at least in the .NET world, for storing such data other than a list appears to be the dictionary, which in the .NET environment, is a generic disallowing the need for boxing and unboxing objects as a result of typing determinations.
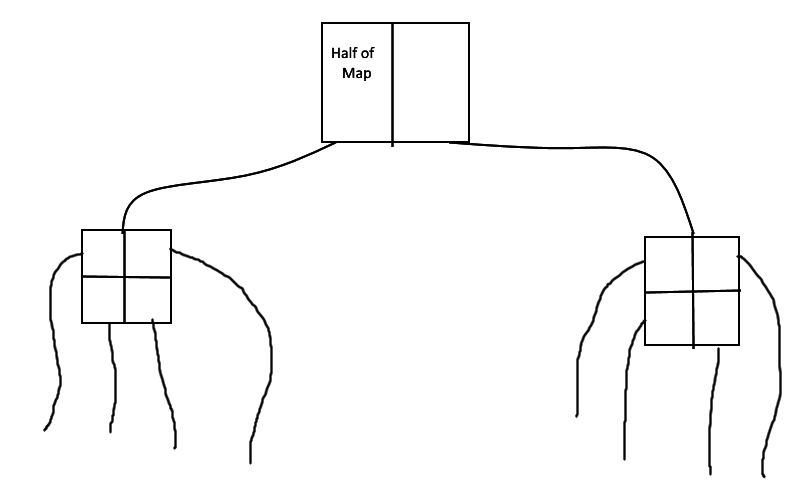
Though I am hardly knowledgeable of QaudTree structures, finding what appears to be a decent explanation of them with C coding examples on Wikipedia (https://en.wikipedia.org/wiki/Quadtree), you may also want to consider the use of the B+Tree, which is probably the most efficient tree structure ever designed. All RDBMS database systems use B+Tree or its variants. Like the QuadTree, standard BTree lists are limited to only two leaf nodes (if I remember my structures correctly), while B+Tree lists can have up to 12 or 24 leaf nodes (I cannot remember which).
In any event, years ago back in the 1990s, a good friend of mine (he was a genius level developer and an internals specialist) took Borland International’s Turbo Database Toolbox, which was based upon a B+Tree design (surprisingly all of the source code for this ISAM database system was made available with its purchase at $65.00 USD) and did internal comparisons and bench-marking with some of the most powerful database algorithms available commercially, including the then very powerful FOCUS database system (his brother was technical representative of the company and so was able to get the source code to study). My friend found even to his amazement that the Borland algorithms created by college graduate students was the most efficient and fastest of them all.
")