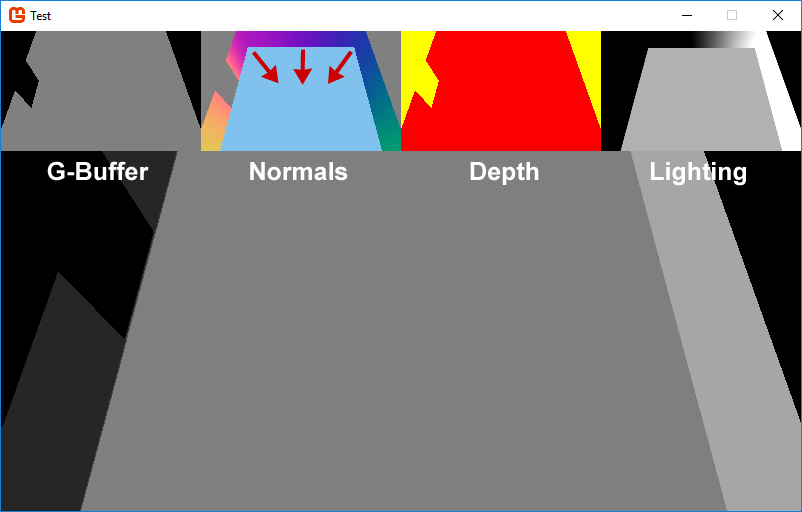
I believe the only unusual thing I do is have the “UnlitFactor” stored in Albedo.w which is used at composition time to output a weighted average of the lit color (color * lighting + specular) and the unlit diffuse color.
Here is the GBuffer shader
// Vertex Shader Constants
float4x4 World;
float4x4 View;
float4x4 Projection;
float4x4 WorldViewIT;
// Color Texture
texture Texture;
// Normal Texture
texture NormalMap;
// Specular Texture
texture SpecularMap;
// Manual Stencil
float UnlitFactor;
// Albedo Sampler
sampler AlbedoSampler = sampler_state
{
texture = <Texture>;
MINFILTER = LINEAR;
MAGFILTER = LINEAR;
MIPFILTER = LINEAR;
ADDRESSU = WRAP;
ADDRESSV = WRAP;
};
// NormalMap Sampler
sampler NormalSampler = sampler_state
{
texture = <NormalMap>;
MINFILTER = LINEAR;
MAGFILTER = LINEAR;
MIPFILTER = LINEAR;
ADDRESSU = WRAP;
ADDRESSV = WRAP;
};
// SpecularMap Sampler
sampler SpecularSampler = sampler_state
{
texture = <SpecularMap>;
MINFILTER = LINEAR;
MAGFILTER = LINEAR;
MIPFILTER = LINEAR;
ADDRESSU = WRAP;
ADDRESSV = WRAP;
};
// Vertex Input Structure
struct VSI
{
float4 Position : POSITION0;
float3 Normal : NORMAL0;
float2 UV : TEXCOORD0;
float3 Tangent : TANGENT0;
float3 BiTangent : BINORMAL0;
};
// Vertex Output Structure
struct VSO
{
float4 Position : POSITION0;
float2 UV : TEXCOORD0;
float3 Depth : TEXCOORD1;
float3x3 TBN : TEXCOORD2;
};
// Vertex Shader
VSO VS(VSI input)
{
// Initialize Output
VSO output;
// Transform Position
float4 worldPosition = mul(input.Position, World);
float4 viewPosition = mul(worldPosition, View);
output.Position = mul(viewPosition, Projection);
// Pass Depth
output.Depth.x = output.Position.z;
output.Depth.y = output.Position.w;
output.Depth.z = viewPosition.z;
// Build TBN Matrix
output.TBN[0] = normalize(mul(float4(input.Tangent, 0), WorldViewIT).xyz);
output.TBN[1] = normalize(mul(float4(input.BiTangent, 0), WorldViewIT).xyz);
output.TBN[2] = normalize(mul(float4(input.Normal, 0), WorldViewIT));
// Pass UV
output.UV = input.UV;
// Return Output
return output;
}
// Pixel Output Structure
struct PSO
{
float4 Albedo : COLOR0;
float4 Normals : COLOR1;
float4 Depth : COLOR2;
};
// Normal Encoding Function
half3 encode(half3 n)
{
n = normalize(n);
n.xyz = 0.5f * (n.xyz + 1.0f);
return n;
//half p = sqrt(n.z * 8 + 8);
//return half4(n.xy / p + 0.5, 0, 0);
}
// Normal Decoding Function
half3 decode(half4 enc)
{
return (2.0f * enc.xyz - 1.0f);
//half2 fenc = enc * 4 - 2;
//half f = dot(fenc, fenc);
//half g = sqrt(1 - f / 4);
//half3 n;
//n.xy = fenc*g;
//n.z = 1 - f / 2;
//return n;
}
// Pixel Shader
PSO PS(VSO input)
{
// Initialize Output
PSO output;
// Pass Albedo from Texture
output.Albedo = tex2D(AlbedoSampler, input.UV);
// Pass Extra - Can be whatever you want, in this case will be a Specular Value
output.Albedo.w = UnlitFactor; // 0.5f;// tex2D(SpecularSampler, input.UV).w;
// Read Normal From Texture
half3 normal = tex2D(NormalSampler, input.UV).xyz * 2.0f - 1.0f;
// Transform Normal to WorldViewSpace from TangentSpace
normal = normalize(mul(normal, input.TBN));
// Pass Encoded Normal
output.Normals.xyz = encode(normal);
// Pass Extra - Can be whatever you want, in this case will be a Specular Value
output.Normals.w = 0.0f;// tex2D(SpecularSampler, input.UV).x;
// Pass Depth(Screen Space, for lighting)
output.Depth = input.Depth.x / input.Depth.y;
// Pass Depth(View Space, for SSAO)
output.Depth.g = input.Depth.z;
// Return Output
return output;
}
// Technique
technique Default
{
pass p0
{
VertexShader = compile vs_3_0 VS();
PixelShader = compile ps_3_0 PS();
}
}
And the directional light shader
// Inverse View
float4x4 InverseView;
// Inverse View Projection
float4x4 InverseViewProjection;
// Camera Position
float3 CameraPosition;
// Light Vector
float3 L;
// Light Color
float4 LightColor;
// Light Intensity
float LightIntensity;
// GBuffer Texture Size
float2 GBufferTextureSize;
//// GBuffer Texture0
//sampler GBuffer0 : register(s0);
//// GBuffer Texture1
//sampler GBuffer1 : register(s1);
//// GBuffer Texture2
//sampler GBuffer2 : register(s2);
// GBuffer Texture0
texture GBufferTexture0;
sampler GBuffer0 = sampler_state
{
texture = <GBufferTexture0>;
MINFILTER = LINEAR;
MAGFILTER = LINEAR;
MIPFILTER = LINEAR;
ADDRESSU = CLAMP;
ADDRESSV = CLAMP;
};
// GBuffer Texture1
texture GBufferTexture1;
sampler GBuffer1 = sampler_state
{
texture = <GBufferTexture1>;
MINFILTER = LINEAR;
MAGFILTER = LINEAR;
MIPFILTER = LINEAR;
ADDRESSU = CLAMP;
ADDRESSV = CLAMP;
};
// GBuffer Texture2
texture GBufferTexture2;
sampler GBuffer2 = sampler_state
{
texture = <GBufferTexture2>;
MINFILTER = POINT;
MAGFILTER = POINT;
MIPFILTER = POINT;
ADDRESSU = CLAMP;
ADDRESSV = CLAMP;
};
// Vertex Input Structure
struct VSI
{
float3 Position : POSITION0;
float2 UV : TEXCOORD0;
};
// Vertex Output Structure
struct VSO
{
float4 Position : POSITION0;
float2 UV : TEXCOORD0;
};
// Vertex Shader
VSO VS(VSI input)
{
// Initialize Output
VSO output;
// Just Straight Pass Position
output.Position = float4(input.Position, 1);
// Pass UV too
output.UV = input.UV - float2(1.0f / GBufferTextureSize.xy);
// Return
return output;
}
// Manually Linear Sample
float4 manualSample(sampler Sampler, float2 UV, float2 textureSize)
{
float2 texelpos = textureSize * UV;
float2 lerps = frac(texelpos);
float texelSize = 1.0 / textureSize.x;
float4 sourcevals[4];
sourcevals[0] = tex2D(Sampler, UV);
sourcevals[1] = tex2D(Sampler, UV + float2(texelSize, 0));
sourcevals[2] = tex2D(Sampler, UV + float2(0, texelSize));
sourcevals[3] = tex2D(Sampler, UV + float2(texelSize, texelSize));
float4 interpolated = lerp(lerp(sourcevals[0], sourcevals[1], lerps.x),
lerp(sourcevals[2], sourcevals[3], lerps.x), lerps.y);
return interpolated;
}
// Phong Shader with UnlitFactor as a manual stencil
float4 Phong(float3 Position, float3 N, float SpecularIntensity, float SpecularPower)
{
// Calculate Reflection vector
float3 R = normalize(reflect(L, N));
// Calculate Eye vector
float3 E = normalize(CameraPosition - Position.xyz);
// Calculate N.L
float NL = dot(N, -L);
// Calculate Diffuse
float3 Diffuse = NL * LightColor.rgb;
// Calculate Specular
float Specular = SpecularIntensity * pow(saturate(dot(R, E)), SpecularPower);
// Calculate Final Product
return LightIntensity * float4(Diffuse.rgb, Specular);
}
// Decoding of GBuffer Normals
float3 decode(float3 enc)
{
return (2.0f * enc.xyz - 1.0f);
//half2 fenc = enc * 4 - 2;
//half f = dot(fenc, fenc);
//half g = sqrt(1 - f / 4);
//half3 n;
//n.xy = fenc*g;
//n.z = 1 - f / 2;
//return n;
}
// Pixel Shader
float4 PS(VSO input) : COLOR0
{
// Get All Data from Normal part of the GBuffer
half4 encodedNormal = tex2D(GBuffer1, input.UV);
// Decode Normal
half3 Normal = mul(decode(encodedNormal.xyz), (float3x3)InverseView);
// Get Specular Intensity from GBuffer
float SpecularIntensity = encodedNormal.w;
// Unlit Factor
float UnlitFactor = tex2D(GBuffer0, input.UV).w;
// Get Specular Power from GBuffer
float SpecularPower = 128;// encodedNormal.w * 255;
// Get Depth from GBuffer
float Depth = manualSample(GBuffer2, input.UV, GBufferTextureSize).x;
// Calculate Position in Homogenous Space
float4 Position = 1.0f;
Position.x = input.UV.x * 2.0f - 1.0f;
Position.y = -(input.UV.x * 2.0f - 1.0f);
Position.z = Depth;
// Transform Position from Homogenous Space to World Space
Position = mul(Position, InverseViewProjection);
Position /= Position.w;
// Return Phong Shaded Value
float4 Light = Phong(Position.xyz, Normal, SpecularIntensity, SpecularPower);
//Light = (1 - UnlitFactor) * Light + UnlitFactor * float4(1, 1, 1, 0);
return Light;
}
// Technique
technique Default
{
pass p0
{
VertexShader = compile vs_3_0 VS();
PixelShader = compile ps_3_0 PS();
}
}