4 months, 1 week, 3 days or 130 days left
EDIT
Countdown Timer - Countdown to 1 Jul 2021 in Los Angeles (timeanddate.com)
No idea how to use these…
4 months, 1 week, 3 days or 130 days left
EDIT
Countdown Timer - Countdown to 1 Jul 2021 in Los Angeles (timeanddate.com)
No idea how to use these…
Has anyone backed up the site yet? If not maybe I’ll make a scraper
I backed up the MXA site to the XNA GameStudio archive some time back. (XNA installers for newer versions of VS)
But they already cleaned the site when they archived it, so there is only source available. Those project I cared about (and sadly there weren’t that many) I already grabbed.
For those unaware, could you link said GitHub collection here?
As far as I can tell there is no existing backup of codeplex anywhere on the internet. Not to my knowledge.
First off, can anyone else find an existing site backup?
If we can’t, then let’s start here, can anyone locate Codeplex’s API? It will be very straightforward to do a site rip if we have access to the API. It may take a week or two depending on how much there is to download.
There are ways to sniff out a website’s API if it’s not made public, but official documentation would be the best obviously.
Good point, you can find the XNA GameStudio Archive here:
SimonDarksideJ/XNAGameStudio: The Education library from the Xbox Live Indie games repository, valuable for MonoGame Developers for advanced samples (github.com)
Contains things like:
Feel free to help out and contribute more if you can.
No point backing it all up, just any interesting XNA projects on there. There are a few but none I’ve sought out to archived that I haven’t already
Scratch that I sniffed out the API and have implemented the search function in a C# program. Now I have it ripping all project IDs and saving it to disk, which it will later download.
Unfortunately, I am done for the day, since it needs to scrape all project URLs before I can continue, which will take a while.
No point?
Just think of the thousands of thousands of collective hours put into projects on Codeplex. Will there be someone else out there who backs it up? Probably. Did I get it done in an afternoon? Yes. So now there’s nothing to worry about.
I doubt the original posters of said content are even aware everything is going down… permanently. I wish we had more time for the data and wish they made it far easier to download the whole lot despite the server load it will bring…
I doubt it will hit over 2-3 TB in total…
Well, GitHub has 1.9 million projects, the API I found won’t let me set the “skip” parameter over 100,000. It does go up to 100,000, though, so that’s at least one terabyte.
O_o
My API lingo is rusty… is there another way to get later entries?
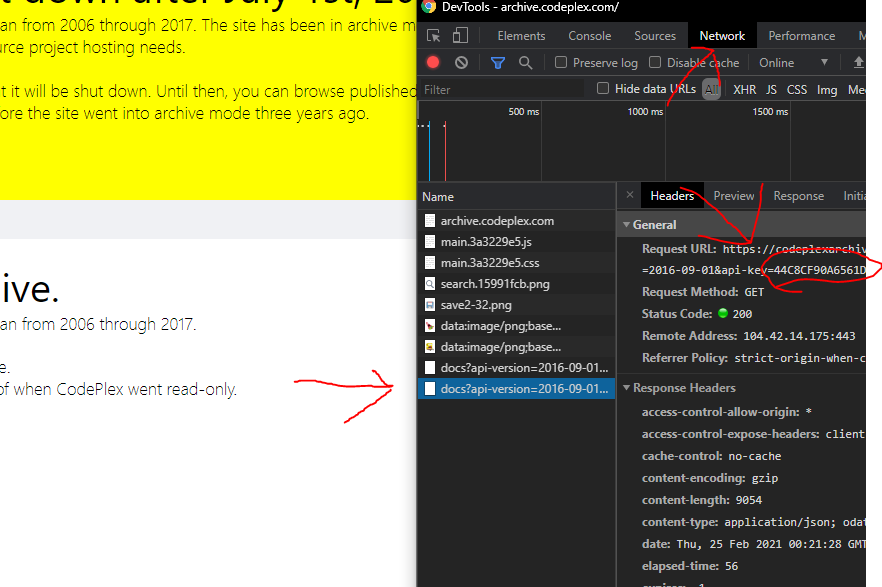
Here’s the entry point I found
https://codeplexarchive-search.search.windows.net/indexes/codeplexarchive-index/docs?api-version=2016-09-01&api-key=( your API key
)&$top=1000&highlight=Title&search=*&$skip=0
So for parameters we have
top
api-key
highlight
search
$skip
I found it using this. It comes with an API key. When you type anything into the search bar you get all kinds of fun stuff
I’ll go into Kali Linux and see what a high quality scan of the site looks like
I was able to scrape 90% of the entire thing (project info and URLs, not the projects yet) using a blank * query.
Now I’m searching ‘a’ through ‘z’ and that should give me the remainder.
If there’s anything left after that it’s made of entirely unicode characters. I’ll try some Japanese characters after that, I see there being entire repositories written in Japanese.
Any other suggestions? Are there any foreign languages that would not use any Japanese or English characters? Probably Chinese? Does anyone know what Chinese characters I should look for? There are a lot of them.
Not sure I want to post the tool I made, I need all of Codeplex’s bandwidth and I don’t want to share it with 30 of you.  I will obviously post the full site rip when I’m done. On r/DataHoarders
I will obviously post the full site rip when I’m done. On r/DataHoarders
I really feel pained about how much data has been dropped from the web concerning XNA…
Mind you… @jamie_yello could you create a dump of this page?
XNA Game Studio 4.0 | Microsoft Docs
Notice all the list on the left, usually Microsoft has a one click button to download the entire thing as a PDF below the list, but that was implemented later…  I have tried sitting there and clicking through everything but… I think I got to 40% and it was a ~5GB behemoth because it was duplicating thousands of files and I suspect that page [those pages] will expire at some point If I could pay you for a coffee or something somehow, let me know!
I have tried sitting there and clicking through everything but… I think I got to 40% and it was a ~5GB behemoth because it was duplicating thousands of files and I suspect that page [those pages] will expire at some point If I could pay you for a coffee or something somehow, let me know!
Sure thing, the Codeplex scraper is about half way done and sitting at 300 GB right now. I didn’t bother scraping the HTML, sorry if anyone felt nostalgic for that.
The Microsoft doc website, we should be able to rip that with some tool someone already made, right? Probably just a basic link crawler should do the trick. Codeplex was trickier because all the content was only available through a search bar.
I appreciate your thanks, but you don’t need to. Now that you point it out, I’d be pretty sad if the XNA documentation we had disappeared forever. And >5 GB of it?? So thank you for pointing it out. Let me know if you can think of anything else that needs to be preserved.
I was active in the flashpoint flash preservation community as well. One day I dropped 15,000 flash files they didn’t have on them and left. XD
I also made them a tool to automatically capture flash screenshots. It would open 50 different SWFs in 50 flash players at once, wait 10 seconds, save their buffers to a PNG and close it. You should have seen that madness. That decrepid 18+ madness. It went on for hours and hours.
Using a program called Cyotek, I’m scraping the entire docs.mocrosoft.com website. I have no idea how it will turn out. Fingers crossed for an easy project.
This is the best scraper I’ve used, actually. Once I’m done I’ll try to use it to scrape archive.codeplex.com again just to see if it works. (I doubt it would, like I said the only content is available through a search query)
Here’s a site rip that targeted specifically the XNA portion of the site. The bar on the left is missing, but otherwise the site is intact. (XNA HTML is in docs.microsoft.com\en-us\previous-versions\windows\xna)
I’m still doing a full site rip, but that will be over 10 GB. Maybe that will fix the bar.
What we can do maybe… we can take the opportunity to make our own index page? I don’t care for the official one anyway. Should be easy if we automate it with a program.
Maybe someone who knows more about HTML can fix the bar. I know very little. Maybe we can figure out what part of the full site is needed to get that bar.
https://mega.nz/file/T4YywbpT#XTbfhWupFWn3H9fjzuJ0qffaEiEop6lVcOK14Q7hv_0
I should just put this up on Github. Is Microsoft going to copyright takedown their own page?
“Don’t put that there!”
Looks like it is using JavaScript code to generate it? only took a quick look…
EDIT
@jamie_yello Dude, it’s perfect! I can use ‘search file contents’ to search within the html files, perfect! for anyone wondering, I have downloaded and scanned the file, which took a good 64seconds to do.

EDIT
Cannot thank you enough!
EDIT
Concerning sites to archive, I can think of a few such as RBW’s site and the like, but I think we can try to ask for permission first? 
| 122 | days |
|---|---|
| 2944 | hours |
to go…
Sure, I’ll ask for permission first I guess. Can’t imagine them saying no.
87793/108508 projects downloaded, 81% done, 628 GB so far. This is going to be done tonight finally. I was afraid it was going to end up being 8 TB and I would have to go out and buy a new hard drive, but no, I don’t even have to uninstall any steam games.
There was also the possibility that it would take a month (or 4 o_o) to finish, which was possible, but thankfully that wasn’t the case.