rbwhitaker brought up the fact that his site was already backed up by the wayback machine
So that brings up the question, what XNA resources did we lose that might be in the wayback machine?
rbwhitaker brought up the fact that his site was already backed up by the wayback machine
So that brings up the question, what XNA resources did we lose that might be in the wayback machine?
WBM backs up text and some images if below a certain size? but not downloads…
What connection you on lol, and epic…!
EDIT
Forum is always broken for me somehow…
WBM crawls websites and just recursively scans them for links. The reason it couldn’t do Codeplex was because there is no way to “scan” a website for all files the way you might think. You can only find links within pages and request those. It can only find static hard-coded links.
This is just generally how all crawlers work. It very clumsily crawls around looking for links until it’s found everything it can.
It can’t scrape anything that’s behind a database, only the user interface elements.
Oh, I meant the first bit, ignore the nagging about the forum being a bother, the reply button is broken…
EDIT
I am confusing myself now… time for some tea…
@jamie_yello by the way, you could use that page I linked originally for the MS Docs dump, and save the page, which will give the complete menu list for reference at the least…
Just a thought…
It’s in there (bb200104) it just doesn’t have working links or themes for whatever reason.
The one in the wayback machine works, but it’s also missing the side bar for whatever reason. I think before we have to worry about using the content, we might as well at least wait for the official XNA documentation to go down. 
BTW, I have finished the scrape and made a torrent, so Codeplex is saved as long as this torrent lives.
Could someone do me a favor and make sure this torrent works? You don’t have to download the whole thing, just confirm that it starts downloading
I could trim the torrent down to projects that were not migrated to discord, I might get around to that so that I don’t waste 600 gb on preservationists’ hard drives, but that would also have to be automated through a program.
Sigh, unable to test this sadly…
GitHub?
Can you break the file up into max size for Mega? all 750GB in say 50GB chunks?
EDIT
LOL nvm, it is max 50GB for free accounts…
Wish there was some other way…
I don’t think my torrent works anyway. Probably should have fixed it by now, but what I think I’ll do is make a website that hosts all the data once codeplex goes down.
I’ll also curate the data so there’s a downloadable version with all projects (750 GB) and a version with just some of the biggest files (that are on github) removed. That should cut down the size to less than 30 GB.
I’ll have it up before Codeplex goes down, but for right now I’ll be taking a break from this.
@MrValentine Let me know if you want me to put it all up on Mega in the meantime, that way Codeplex isn’t lost even if my house burns down or I die or get amnesia or something. I can do that pretty quickly.
Happy to store it, currently sitting on roughly 30TB empty… I think removing any projects is not important and would be an insane amount of work anyway.
Thanks for your skillset and efforts 

Sure, the only reason I’m good at this is that I’ve made many web scapers before, I think at least 5, for some reason. Every time I get a little better. I first started by downloading HTML as a string and using string.IndexOf() to look for data, then I realized APIs are a thing. I will say, I’m not sure if a Selenium web scraper has the same limitations of an API based scraper when it comes to API call restrictions. I’m thinking a Selenium scraper may be bypass call restrictions by virtue of imitating a user, but that’s some techno jargon.
If you want to do a really accurate site rip, the most accurate you can, you have to use Selenium. It basically hooks into a modern web browser (Chrome) and gives you control over it through code. One of my favorite things to use. I tried to use it to automatically buy Bitcoin on Robinhood based off my machine learning models. XD That didn’t turn out well.
Now I’m moving on to scraping Stocktwits comments to find the most accurate investors and storing all the data in a real SQL database as opposed to one bloated XML file that has to be recreated entirely to modify at all.
Did you hear that the reason for GTA’s long loading screen is one single extremely poorly done method that loads one JSON file every single time the game loads anything? It makes me hurt inside.
Anyways hopefully 7zip and Mega will be done compressing/uploading the data… tomorrow.
Thanks for the insight 
That company, oh boy, yes, they managed to make something somewhat impressive, but on the fundamentals, and now the whole gambling system… nah, avoiding…
It’s on Wayback
https://web.archive.org/web/20210212000649/https://shawnhargreaves.com/blogindex.html
That scraper may work but I prefer to make my own. A lot of the scraping tools I’ve run into often just don’t work and there’s no way for me to fix them. It might be a personal preference, but when something’s stopping me from getting a project done I prefer it be myself.
And BTW… I’ll have that upload completed in 7 days. You’ll have to pay €10 for Mega’s “standard” plan if you want to download it. XD
Here’s to hoping Windows doesn’t forcefully restart my computer before then. Ugh, I would switch back to PopOS, but as a developer you kind of need Windows.
Really prefer local, wayback is a ball ache to navigate ![]()
DM me with your PayPal when ready ![]()
EDIT
WBM is refusing to connect for me ![]() EDIT Seems to be an issue with my landline fibre connection EDIT The website refuses to connect
EDIT Seems to be an issue with my landline fibre connection EDIT The website refuses to connect ![]() will try the laptop to see if that helps EDIT Nope, so weird… it’s as though my router is blocking archive.org, but pretty sure I used it not long ago? EDIT It is my content blocker, but wtf, PHub works !?
will try the laptop to see if that helps EDIT Nope, so weird… it’s as though my router is blocking archive.org, but pretty sure I used it not long ago? EDIT It is my content blocker, but wtf, PHub works !?
EDIT
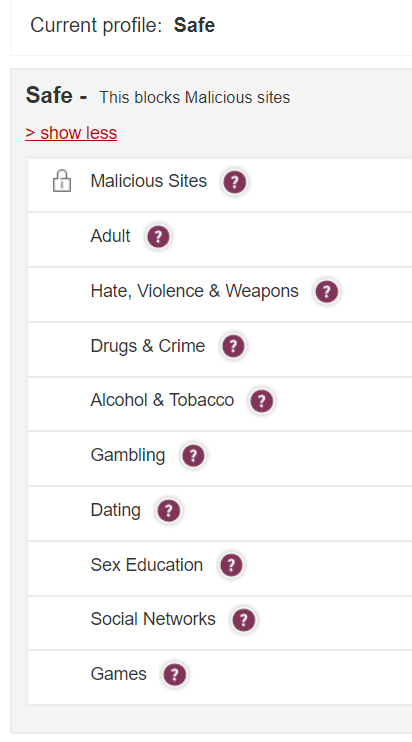
It appears to be that archive.org is a malicious site lol:
EDIT
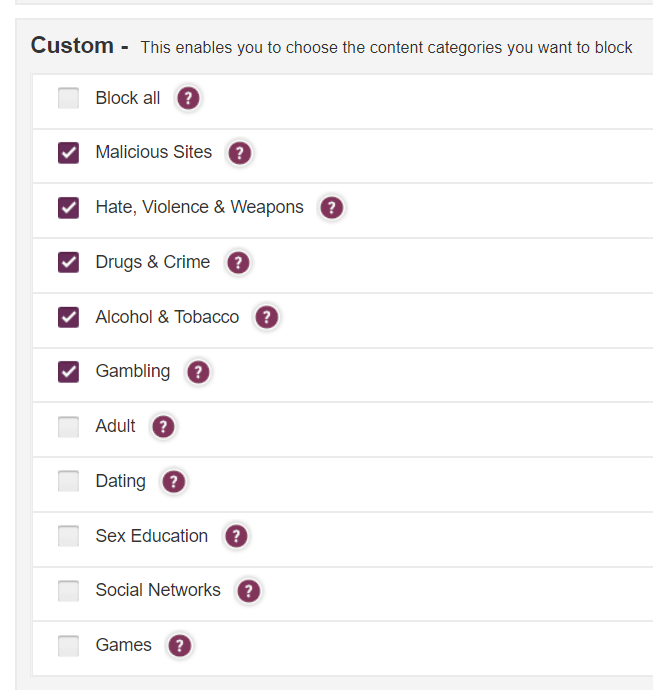
Added to safe list and changed my settings as so:
Wondering if it blocks ads from social certain sites now lol
I’ll share that site as well then just so we can be safe
XNA | Catalin ZZ (catalinzima.com)
 just found this gem
just found this gem
Wow, I’ll read that myself.
39% uploaded btw
Oh no, after 5 days of uploading the Mega page is lagging like hell.
Good thing I split it up into multiple files.  I may not be smart enough to set up a torrent but I managed to see that one coming.
I may not be smart enough to set up a torrent but I managed to see that one coming.
Here’s 39% of the files.