I got my shaders working decently now, doing point light with normal and parallax mapping. Performance is not great. I want to do hardware instancing because I’m drawing a lot of the same mesh (walls). Have it set up correctly, I think, in my C# code. My issue is this: In order to correctly draw my normal maps, I need the unscaled world matrix in my shader. Pre-instancing, I was passing it as a shader parameter. However, using DrawInstancedPrimitives, it looks like I can only pass one matrix as a parameter to the vertex shader. How do I get the unscaled world matrix for my normal map calcs?
1: Is there a way to derive the unscaled world matrix from the fully transformed world matrix? If so, I could do this in the vertex shader.
2: If not, is there a way to pass two matrices to the shader from DrawInstancedPrimitives? The shader compiles correctly when I add another parameter to the input of the vertex shader (float4x4 WorldInstanceRotationInverseTranspose : BLENDWEIGHT) but I don’t know how to actually get that parameter to the shader from the call to DrawInstancedPrimitives.
3: Or is there just some better / other way to do this that I’m not seeing?
Yeah, if you normalize the first 3 columns of the matrix, the scale is gone.
With instancing you usually use 2 vertex buffers. One for the mesh, and one with all the instance data. You can easily put two matrices into the instance data vertex buffer. You have to use GraphicsDevice.SetVertexBuffers to set both buffers simultaneously.
This is how I have it now, but I think I’m doing the instancing wrong because my shader is drawing literally nothing, not even black - just nothing, even when I’m using a one-line pixel shader that only returns the color of the texture at the given texcoord. I’m using GraphicsDevice.SetVertexBuffers, but I am passing a world transform for each ModelMesh. Should I be passing one for each MeshPart instead? I have a few incomplete examples I’m trying to piece together to make it work, and it’s not clear how to build the instancing group of matrices. I think I have everything I need, I’m just not sure how to put it all together.
For the unscaled world matrix you only want to normalize the xyz-components, don’t include w. You can also make it a float3x3, since you are only interested in rotations, but then you should probably also call it worldRotation.
As for the instancing, it’s hard to diagnose the problem without seeing code, based on your decription alone. It sounds like you don’t properly undestand yet how to use instancing.
If you have a model that consists of multiple mesh parts, you can’t really instance the whole model at once. You would need to instance the meshes separately. The point of instancing is, you have one mesh/vertexbuffer, and you draw that many times.
Just a hint because you mentioned drawing walls - which are normally pretty static. I guess you draw each wall with its own drawcall.
You can simply combine the wallpieces into a single mesh and draw that. You can also subdivide the world into bigger chunks to not always render the whole world.
Instanced Geo does exactly that - minimizing lots of draw calls into one and as your geo isnt changing (walls) - a combined mesh will yield more performance than instancing would and maybe easier to handle as well as you wouldnt need to change your shader at all (and you spare a lot of data).
Instancing is nice, when individual pieces behave individually. For just static geo, it’s better to just combine it into a single mesh.
@markus Thanks, that seemed to do the trick. I wasn’t sure how to access just the xyz from each column until I realized I could just do worldRotation[index].xyz.
@reiti.net Yes that’s what I’ve noticed, now that I have it all working, the performance does not seem any better than when I was just using mesh.Draw(). In fact, maybe worse. These walls are very simple, they are cube meshes with one axis scaled so that they are very thin. The mesh itself has 12 vertices. So maybe instancing isn’t useful for this type of object. I’ve noticed the main issue with performance are the wall textures - I have some really nice textures, but using them as opposed to lower res textures causes a big performance hit. I have scaled down the good textures from 4k to 1k which helps. I was thinking as an object is further away from the camera, I could use lower res versions of the textures too since the player won’t be able to see any level of detail anyway. But is there any other way to help improve performance from a texture standpoint other than just using lower res textures?
Do they even need to have any thickness, or could it just be a 4 vertex quad?
I find it difficult to imagine that the textures are causing such a big performance problem. IIRC your nomal map shader does 2 texture lookups per pixel. That’s not a lot these days. The only way to get into serious perf problems is if you have massive overdraw. Are you drawing a lot of walls on top of other walls?
That happens automatically if your textures use mipmapping, which should be the default behaviour. Make sure you have the GenerateMipmaps option enabled in the content pipeline.
They do not have any thickness, they could probably just be 4 vertex quads - that is a good point.
I don’t think I’m drawing walls on top of each other as I do check for duplicates. I have 779 walls drawing in total when I check my walls array, which sounds correct. I have GenerateMipMaps enabled. It helps to do things like not draw any walls outside of current light range of course, but I still seem some framerate issues. I have other low-poly models drawing on the scene too, but the main impact appears to be the wall textures based on my testing so far.
When I draw using BasicEffect, performance is excellent and I don’t notice any issues. When I draw using my shader, I have good performance when drawing with a 512 texture, but the performance is impacted significantly when I go up to a 1024 texture. And the instancing doesn’t seem to help at all.
This is my current pixel shader, it needs cleanup and it now samples texture 3 times with the addition of the height map, but maybe there’s something else I need to optimize? I moved some of the calculations to the vertex shader and passed those as input variables to the pixel shader but that really didn’t seem to help much.
I am making the assumption that the pixel shader is much more impactful to performance since it gets called per-pixel while while the vertex shader is per vertex but maybe I’m wrong about that.
The one thing in this shader, that GPU’s don’t like, is the unpredictable uv coordinates:
As long as adjacent pixels sample adjacent texels from the texture the caching will work well. As the heighmap becomes more erratic, performance will go down. Can you check if removing this uv shift, or reducing scaleBias, solves your perf problem?
Definitely works better when I remove that line. Does that mean I can’t do parallax mapping the way I was doing it without taking a big performance hit? Even with reduced scale bias, the performance is still far better without it at all.
Still even with the uv shift, the 512 texture work great while the 1024 ones are slow.
it is a bit weird, as it shouldnt make that much difference for the GPU - cache misses shouldnt have that big of an impact in regards to the general nature of parallel processing and modern cache sizes. But well … who knows. on systems with shared memories or other things, many cases are possible.
anyway. if you comment that single line out, the compiler will actually remove the whole conditional (“if”), I do guess it’s a shader constant anyway and may be resolved be the shader compiler, but just for the sake of curiousity, you could try to remove the if and make the parallax mandatory? just to make sure it’s not some thing of render pipeline stalling due to branching.
I do parallax in my voxel game as well and with a lot more texture data and have not found any unusual performance impact from it - not saying it couldn’t happen, I would just wonder, that’s why I would try to rule out other things first, like branching
btw. yes many ppl will say, that “if” is bad in every shader - it’s more complex than that, there is good and there is bad "if"s, your’s shouldn’t be an issue, and it goes beyond the scope to talk about it, but generally you want that every call to the PixelShader will result in the same amount of instructions for every pixel on the screen.
It does sound a bit weird. It almost sounds like you are drawing more pixels then it seems.
Can you give some concrete performance results? What fps do you get with and without the parallax? What GPU are you on. How many pixels in total are being rendered roughly?
Can you easily test a single fullscreen wall using this shader? I’d be interested how that performs.
I improved performance in a number of key ways (frustrum culling, and exiting the pixel shader when attenuation is < 0) which definitely helps, but I still see framerate drops when I have lots of walls in field of view.
Directly facing a wall so the wall takes up the entire screen, steady 60 FPS which is what I have my framerate set for.
In a large room with many walls far away, framerate drops to 45 FPS.
Using BasicEffect, I get 60 FPS in same large room. With my shader, I get 45.
If I change JUST this line on my shader:
float nDotL = saturate(dot(normal, lightDir));
To this:
float nDotL = 1.0f;
My FPS goes up to 60.
Current shader code for context, I cut out a lot of stuff to isolate the issue:
For performance tests you need to set GraphicsDevice.SynchronizeWithVerticalRetrace = false, so you are not capped at 60 fps. What resolution are you running at? To find out which GPU you have, you can launch dxdiag. If you type dxdiag into the Windows 10 search field, you’ll find it.
I’m running the game at 800 x 480 resolution for now. GPU is Intel HD Graphics 530.
With GraphicsDevice.SynchronizeWithVerticalRetrace = false, and drawing nothing else in game except the walls, floors and ceiling, which are same mesh, I get this:
Dot product commented out in the shader:
300 FPS when facing directly in front of a wall
90 FPS when facing out into the large room.
Using dot product in the shader:
250 FPS when facing directly in front of a wall
45 FPS when facing out into the large room.
Draw is called 94 times when facing out into the room (as opposed to 5 when facing the wall; due to wall/floor/ceiling/adjacent walls are still in view). I must be missing something because it doesn’t seem like all that many draw calls to cause an FPS drop like that. I’m surprised that the dot function in the shader is doing so much damage to performance.
Also I think it’s calling draw on objects that are behind other objects. I have DepthBufferEnable = true so everything looks correct, but is there a way for me to tell it not to even hit the shaders of things that are not going to be drawn due to depth buffer? I’m pretty sure some of those 94 draw calls are for rooms below and to the sides that aren’t actually visible after the depth buffer processing.
UPDATE
I read up on occlusion culling, and sorting my draw list by distance to the camera seems to help somewhat.
With an integrated GPU like this you couldn’t call this a gaming laptop when it was new, and it’s getting a little old.
Nevertheless, I find your performance results pretty poor, considering the low resolution and simple shader.
You said before that you had it running with hardware instancing, and performance wasn’t any better. The instancing should have gotten rid of draw call overhead, unless you did something wrong. That would indicate that your performance drop is mostly pixel fillrate related.
If it is indeed fillrate, then this large fps drop would indicate that there is a lot of overdraw in the second case.
That’s not really surprising. Removing the dot function will effectively eliminate the lines above it too, including the sampling of the normal map.
It seems like a dungeon like this should be a relatively easy case for visibility optimizations. You start at the camera’s location and figure out which walls can be seen.
Thanks markus, with those optimizations in place and culling based on scene visibility (didn’t realize i had to manually do that even with DepthBufferEnable = true), I’m no longer seeing any performance issues. Appreciate all the help again!
FYI: In order for depthchecks to work, the vertex shader has to run anyway - it’s just clipping then but it still does a lot of stuff - same is true for actual screenspace culling. So whatever you send to the GPU will at least utilize the VertexShader as a whole, as the screen position is simply not known until the vertexshader finished
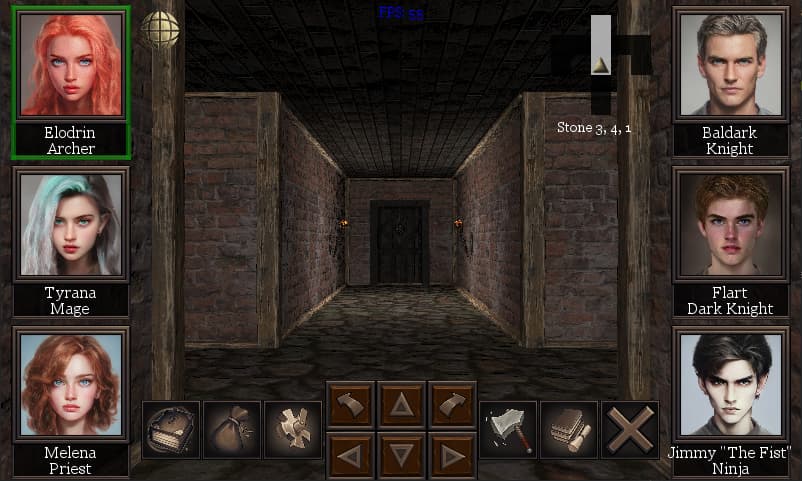
Here’s a screenshot of the blobber I am working on, using my new optimized shader and renderer with multiple point lights and normal mapping working (I think) correctly. I removed the parallax mapping for now for performance issues, but it really doesn’t seem to need it. Also I turned off instancing for now, but at least I can switch to that if I need to in the future - maybe for the wooden framing, which has a lot more vertices than the flat walls. Thanks guys, I’m really happy with how it is looking and I understand a lot more about shaders now too.