I’m trying to implement soft particles in a deferred rendering context but when the camera is to far away, then the reconstruction of the scene depth is not good enough. At the moment I calculate z/w in the pixel shader and encode this value to the first three channels of a RenderTarget.
How does storing a linear depth value work? Do I just need to calculate something like “camera space z value / far plane distance”?
I will update the deferred rendering thread as soon as I find the time to work on the project.
When using MRT (Multiple Render Targets) it is possible to use RenderTargets with different SurfaceFormat I guess? (Because I would change the depth Render Target to SurfaceFormat.Single).
Is it possible to reconstruct world space position from depth using the far plane frustum corners in world space directly without multiplying with the inverse view matrix?
So if I use the GetCorners method of the BoundingFrustum class, they are in world space. Then the next step would be, to substract the camera position and pass these over to the shaders?
I had an redundant line of code in the middle. A normalization which of course is not necessary in this case. I mixed some things up when I wrote the code.
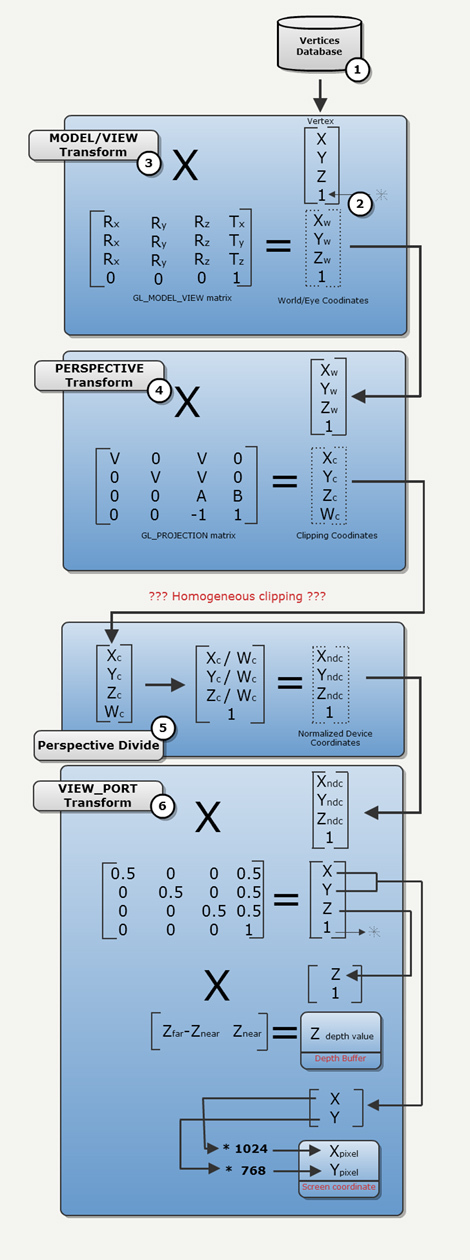
I’ve got a question concerning depth z/w vs linear depth.
If i need to do forward rendering after all the deferred stuff with a linear depth, there are two options:
-linearize forward renders : so it would need a shader because basic effect cant do it in the shader or do it on cpu when sending the matrix? Gpus are faster for matrices transforms
-recompute the linear depth to its z/w component
1 . You do the normal forward rendering as you always would - same as Gbuffer setup. Draw your meshes, send them to the GPU together with world * view * projection.
In the vertex buffer transform both to world view projection and world view. Use world view to check against the depth buffer in the pixel shader to discard.
2 . (Probably better)
Recreate the z/w depth buffer by drawing a fullscreen quad and then render your forward rendered meshes like you always would.
In case you want a sample implementation I think my ReconstructDepth.fx from the deferred Engine is ok (You find it in Shaders / ScreenSpace / ReconstructDepth.fx )
I only need (for the moment…) forward rendering for the editor, to draw lights, their volume, etc. But if I need to use forward for translucent things for ex, i will have to think about this.
Thanks, I already have the maths needed But I’m wondering if it is worth the effort to use linear depth, and if speed will not suffer a little with these computations, as monogame in wpf is already a little less fast as the game itself
I would go with option 2 explained by @kosmonautgames, this is also what I was doing while using z/w depth.
Yes, it’s simpler with z/w depth. If you don’t need the precision I would stick with z/w. I had the z/w depth encoded to 24 bits (rgb channels) too. So perhaps it would have been enough to just store the z/w depth in a RenderTarget with SurfaceFormat.Single.
As I don’t need “killer” precision on depth, I may just change for 1-(z/w) which seems enough.
I have also read on nvidia there is a trick: reversing near and farplane. I’ll investigate into this.
Is it better to create the linear depth value
-in viewspace (ie after posworldview)
or
-in clip space (/homogenous instead of making the divide by w) ?


 But I’m wondering if it is worth the effort to use linear depth, and if speed will not suffer a little with these computations, as monogame in wpf is already a little less fast as the game itself
But I’m wondering if it is worth the effort to use linear depth, and if speed will not suffer a little with these computations, as monogame in wpf is already a little less fast as the game itself